
| 강의 개요 | 1. 빅데이터 적재 개요_ 빅데이터 대용량 파일 적재의 기본 개념 설명 2. 빅데이터 적재에 활용하는 기술 _ 하둡, 주키퍼에 대한 소개 , 기술별 주요 기능, 아키텍처 활용방안 3. 적재 파일럿 실행 1단계 _ 적재 아키텍처 : 로그파일 적재와 관련한 요구사항 구체화, 파일럿 아키 설명 4. 적재 파일럿 실행 2단계 _ 적재 환경구성 : 스마트카 로그 파일 적재 아키텍처를 설치 및 환경구성 5. 적재 파일럿 실행 3단계 _ 적재 기능구현 : 플럼이용해 스마트카 생태정보 르그파일 하둡적제기능구현 6. 적재 파일럿 실행 4단계 _ 적재 기능 테스트 : 로그 시뮬레이터 이용해 스마트카 상태 정보 데이터 발생, 플럼이 해당 데이터를 HDFS정상적재 확인 |
| 적재 유형 | 수집 -> 적재(배치성) -> (처리 /탐색 -> 분석/응용) : 배치성. -> 적재(실시간성)-> 적재- 대용량 : 배치성 처리 적재- 메시지 : 실시간성 처리. |
| 적재 저장소 유형 | 1. 내/외부 원천데이터 정형 데이터 : 데이터베이스 (관계/계층/객체/네트워크) 반정형 데이터 : HTML, XML, JSON, 서버로그 비정형 데이터 : 소셜미디어, 문서, 이미지, 오디어 , 비디오 , IOT --------------> 배치수집 실시간 수집 --------------> 2, 적재 저장소 유형. - 배치처리 : 큰파일 대용량 파일 전체를 영구 저장 - 분산파일 시스템 - 실시간처리 : 작은메시지 대규모 메시지 전체를 영구저장 -No-SQL :Hbase, 카산드라, 몽고DB 대규모 메시지 전체를 버퍼링처리 - MoM : 카프카 대규모 데이터 일부만 임시저장 - Cached : 인메모리 캐시시스템 : 레디스. |
에코시스템 : 생태계
| 적재 요구사항 | 1. 차량의 다양한 장치로부터 발생하는 로그 파일을 수집해서 기능별 상태를 점검한다. >> 배치 2. 운전자의 운행정보가 담긴 로그를 실시간으로 수집해서 주행패턴을 분석한다 >> 운전자 운행로그. 이벤트로그 실시간. |
| 적재 요구사항 구체화 |
1. 100대에 달하는 스카트카들의 상태정보가 일단위로 취합 >> 플럼에서 수집 발생시점의 날짜를 HdfsSink에 전달해서 해당 날짜 단위로 적재 logSink -> HdfsSink 2. 매일 100 대의 스마트카 상태 정보는 약 100MB정도이며 220만건의 상태정보 발생 >> 1년 적재시 8억건 이상의 데이터가 적재되며, 연 단위분석에 하둡의 분산병렬처리사용. 3. 스마트카의 상태 정보 데이터의 발생일과 수집/적재되는 날짜가 다를수 있다. >> 수집/적재되는 모든 데이터마다 데이터 발생일 외에 수집/적재 처리돼야 하는 처리일 추가. 4. 적재된 스마트카들의 상태 정보를 일/월/년 단위로 분석할수 있어야 한다. >> HDFS에 수집 일자별로 디렉터리 경로를 만들어 적재. 5. 적재 및 생성되는 파일은 HDFS의 특성을 잘 고려해야 한다. >> 플럼의 HdfsSink의 옵션을 파일럿 프로젝트의 HDFS에 최적화 해서 설정 6. 적재과 완료된 후에는 원천 파일이 삭제되어야 한다. >> 플럼Source 컴포넌트 중 SpoolDir DeletePolicy 옵션을 활용. |
| 적재 아키텍처 |  차량상태정보 100MB/1일 -> 플럼에이전트(SpoolDir Source -> Memory Cannel-> HDFS Sink) -> 일단위 적재 -> 하둡 하둡: -NameNode -DataNode - HDFS : 경로 ... 일별분석, 주, 워별분석.. 년별분석 -맵리듀스 |
 |
|
| 하둡 설치 확인 | CM> HDFS 상세 > DataNode > DataNode웹ui URL : http://server01.hadoop.com:9870/dfshealth.html CM> YARN 상세 > 웹ui > 리소스메니저 리소스매니저 : http://server01.hadoop.com:8088/cluster CM> YARN 상세 > 웹ui > 히스토리 잡 히스토리 : http://server01.hadoop.com:19888/jobhistory cf_ http://server01.hadoop.com:7180/ 클라우데라 매니저. |
| 적재기능구현 -스마트카 에이전트수정. |
SmartCar_Agent.sources = SmartCarInfo_SpoolSource DriverCarInfo_TailSource SmartCar_Agent.channels = SmartCarInfo_Channel DriverCarInfo_Channel SmartCar_Agent.sinks = SmartCarInfo_HdfsSink DriverCarInfo_KafkaSink SmartCar_Agent.sources.SmartCarInfo_SpoolSource.type = spooldir SmartCar_Agent.sources.SmartCarInfo_SpoolSource.spoolDir = /home/pilot-pjt/working/car-batch-log SmartCar_Agent.sources.SmartCarInfo_SpoolSource.deletePolicy = immediate SmartCar_Agent.sources.SmartCarInfo_SpoolSource.batchSize = 1000 SmartCar_Agent.sources.SmartCarInfo_SpoolSource.interceptors = timeInterceptor typeInterceptor collectDayInterceptor filterInterceptor SmartCar_Agent.sources.SmartCarInfo_SpoolSource.interceptors.timeInterceptor.type = timestamp SmartCar_Agent.sources.SmartCarInfo_SpoolSource.interceptors.timeInterceptor.preserveExisting = true SmartCar_Agent.sources.SmartCarInfo_SpoolSource.interceptors.typeInterceptor.type = static SmartCar_Agent.sources.SmartCarInfo_SpoolSource.interceptors.typeInterceptor.key = logType SmartCar_Agent.sources.SmartCarInfo_SpoolSource.interceptors.typeInterceptor.value = car-batch-log SmartCar_Agent.sources.SmartCarInfo_SpoolSource.interceptors.collectDayInterceptor.type = com.wikibook.bigdata.smartcar.flume.CollectDayInterceptor$Builder SmartCar_Agent.sources.SmartCarInfo_SpoolSource.interceptors.filterInterceptor.type = regex_filter SmartCar_Agent.sources.SmartCarInfo_SpoolSource.interceptors.filterInterceptor.regex = ^\\d{14} SmartCar_Agent.sources.SmartCarInfo_SpoolSource.interceptors.filterInterceptor.excludeEvents = false SmartCar_Agent.channels.SmartCarInfo_Channel.type = memory SmartCar_Agent.channels.SmartCarInfo_Channel.capacity = 100000 SmartCar_Agent.channels.SmartCarInfo_Channel.transactionCapacity = 10000 SmartCar_Agent.sinks.SmartCarInfo_HdfsSink.type = hdfs SmartCar_Agent.sinks.SmartCarInfo_HdfsSink.hdfs.path = /pilot-pjt/collect/%{logType}/wrk_date=%Y%m%d SmartCar_Agent.sinks.SmartCarInfo_HdfsSink.hdfs.filePrefix = %{logType} SmartCar_Agent.sinks.SmartCarInfo_HdfsSink.hdfs.fileSuffix = .log SmartCar_Agent.sinks.SmartCarInfo_HdfsSink.hdfs.fileType = DataStream SmartCar_Agent.sinks.SmartCarInfo_HdfsSink.hdfs.writeFormat = Text SmartCar_Agent.sinks.SmartCarInfo_HdfsSink.hdfs.batchSize = 10000 SmartCar_Agent.sinks.SmartCarInfo_HdfsSink.hdfs.rollInterval = 0 SmartCar_Agent.sinks.SmartCarInfo_HdfsSink.hdfs.rollCount = 0 SmartCar_Agent.sinks.SmartCarInfo_HdfsSink.hdfs.idleTimeout = 100 SmartCar_Agent.sinks.SmartCarInfo_HdfsSink.hdfs.callTimeout = 600000 SmartCar_Agent.sinks.SmartCarInfo_HdfsSink.hdfs.rollSize = 67108864 SmartCar_Agent.sinks.SmartCarInfo_HdfsSink.hdfs.threadsPoolSize = 10 SmartCar_Agent.sources.SmartCarInfo_SpoolSource.channels = SmartCarInfo_Channel SmartCar_Agent.sinks.SmartCarInfo_HdfsSink.channel = SmartCarInfo_Channel SmartCar_Agent.sources.DriverCarInfo_TailSource.type = exec SmartCar_Agent.sources.DriverCarInfo_TailSource.command = tail -F /home/pilot-pjt/working/driver-realtime-log/SmartCarDriverInfo.log SmartCar_Agent.sources.DriverCarInfo_TailSource.restart = true SmartCar_Agent.sources.DriverCarInfo_TailSource.batchSize = 1000 SmartCar_Agent.sources.DriverCarInfo_TailSource.interceptors = filterInterceptor2 SmartCar_Agent.sources.DriverCarInfo_TailSource.interceptors.filterInterceptor2.type = regex_filter SmartCar_Agent.sources.DriverCarInfo_TailSource.interceptors.filterInterceptor2.regex = ^\\d{14} SmartCar_Agent.sources.DriverCarInfo_TailSource.interceptors.filterInterceptor2.excludeEvents = false SmartCar_Agent.sinks.DriverCarInfo_KafkaSink.type = org.apache.flume.sink.kafka.KafkaSink SmartCar_Agent.sinks.DriverCarInfo_KafkaSink.topic = SmartCar-Topic SmartCar_Agent.sinks.DriverCarInfo_KafkaSink.brokerList = server02.hadoop.com:9092 SmartCar_Agent.sinks.DriverCarInfo_KafkaSink.requiredAcks = 1 SmartCar_Agent.sinks.DriverCarInfo_KafkaSink.batchSize = 1000 SmartCar_Agent.channels.DriverCarInfo_Channel.type = memory SmartCar_Agent.channels.DriverCarInfo_Channel.capacity= 100000 SmartCar_Agent.channels.DriverCarInfo_Channel.transactionCapacity = 10000 SmartCar_Agent.sources.DriverCarInfo_TailSource.channels = DriverCarInfo_Channel SmartCar_Agent.sinks.DriverCarInfo_KafkaSink.channel = DriverCarInfo_Channel |
| 플럼의 사용자정의 Interceptor 추가 | /opt/cludera/parcels/CDH/lib/flume-ng/lib 파일업로드. bigdata.smartcar.flume-1.0.jar |
| 0. 시뮬레이터 실행. cd /home/pilot-pjt/working $ java -cp bigdata.smartcar.loggen-1.0.jar com.wikibook.bigdata.smartcar.loggen.CarLogMain 20160102 100 & $ tail -f /home/pilot-pjt/working/SmartCar/SmartCarStatusInfo_20160102.txt -이번엔통과 $ java -cp bigdata.smartcar.loggen-1.0.jar com.wikibook.bigdata.smartcar.loggen.DriverLogMain 20160102 3 & $ tail -f /home/pilot-pjt/working/driver-realtime-log/SmartCarDriverInfo.log 1. 일간 로그파일을 플럼 SmartCarInfo 에이전트의 SpoolDir 경로로 옮긴다. SpoolDir (car-batch-log) -> Channel -> HDFS Sink -> HDFS $ mv /home/pilot-pjt/working/SmartCar/SmartCarStatusInfo_20160102.txt /home/pilot-pjt/working/car-batch-log/ --안되서.ㅜㅜ cp로... 필요없음 통과. cp /home/pilot-pjt/working/SmartCar/SmartCarStatusInfo_20160102.txt /home/pilot-pjt/working/car-batch-log/ $cd /home/pilot-pjt/working/car-batch-log/ $ls -ltr 3. 플럼로그 정상확인 $tail -f /var/log/flume-ng/flume-cmf-flume-AGENT-server02.hadoop.com.log 2021-05-27 13:14:27,620 INFO org.apache.flume.sink.hdfs.BucketWriter: Creating /pilot-pjt/collect/car-batch-log/wrk_date=20210527/car-batch-log.1622088824229.log.tmp 2021-05-27 13:14:55,557 INFO org.apache.flume.client.avro.ReliableSpoolingFileEventReader: Last read took us just up to a file boundary. Rolling to the next file, if there is one. 2021-05-27 13:14:55,557 INFO org.apache.flume.client.avro.ReliableSpoolingFileEventReader: Preparing to delete file /home/pilot-pjt/working/car-batch-log/SmartCarStatusInfo_20160102.txt 2021-05-27 13:16:40,491 INFO org.apache.flume.sink.hdfs.BucketWriter: Closing idle bucketWriter /pilot-pjt/collect/car-batch-log/wrk_date=20210527/car-batch-log.1622088824229.log.tmp at 1622089000491 2021-05-27 13:16:40,491 INFO org.apache.flume.sink.hdfs.HDFSEventSink: Writer callback called. 2021-05-27 13:16:40,491 INFO org.apache.flume.sink.hdfs.BucketWriter: Closing /pilot-pjt/collect/car-batch-log/wrk_date=20210527/car-batch-log.1622088824229.log.tmp 2021-05-27 13:16:40,516 INFO org.apache.flume.sink.hdfs.BucketWriter: Renaming /pilot-pjt/collect/car-batch-log/wrk_date=20210527/car-batch-log.1622088824229.log.tmp to /pilot-pjt/collect/car-batch-log/wrk_date=20210527/car-batch-log.1622088824229.log Creating /pilot-pjt/ ~~ : 적재중 BucketWriter: Closing /pilot-pjt/ ~~ BucketWriter: Renaming /pilot-pjt/coll ~~ :: HDFS 적재 성공적으로 끝남. 4. hdfs 적재 확인 $hdfs dfs -ls -R /pilot-pjt/collect/car-batch-log [root@server02 working]# hdfs dfs -ls -R /pilot-pjt/collect/car-batch-log drwxr-xr-x - flume supergroup 0 2021-05-27 13:27 /pilot-pjt/collect/car-batch-log/wrk_date=20210527 -rw-r--r-- 1 flume supergroup 68303437 2021-05-27 13:14 /pilot-pjt/collect/car-batch-log/wrk_date=20210527/car-batch-log.1622088824228.log -rw-r--r-- 1 flume supergroup 55195294 2021-05-27 13:16 /pilot-pjt/collect/car-batch-log/wrk_date=20210527/car-batch-log.1622088824229.log $hdfs dfs -cat /pilot-pjt/collect/car-batch-log/wrk_date=20210527/car-batch-log.1622088824228.log $hdfs dfs -tail /pilot-pjt/collect/car-batch-log/wrk_date=20210527/car-batch-log.1622088824228.log 플럼넣기전 : /home/pilot-pjt/working/SmartCar/, /home/pilot-pjt/working/car-batch-log/ -rw-r--r-- 1 root root 104070631 May 27 13:11 SmartCarStatusInfo_20160102.txt 20160102000100,R0001,94,88,96,98,1,1,1,1,B,B,92 20160102000104,R0001,82,90,79,82,1,1,1,1,A,A,73 20160102000108,R0001,88,93,89,95,1,1,1,1,A,A,93 hdfs에서 : ",20210527" 끝에 작업일자 추가됨. 플럼의 인터셉터가 붙임. 104070631->64M 1개, +나머지 20160102000100,R0001,94,88,96,98,1,1,1,1,B,B,92,20210527 20160102000104,R0001,82,90,79,82,1,1,1,1,A,A,73,20210527 20160102000108,R0001,88,93,89,95,1,1,1,1,A,A,93,20210527 5. 시뮬레이터 종료. |
|
| 마치며. | 1. 빅데이터 적재 개요 2. 빅데이터 적재에 활용하는 기술 : 주요기능, 이키텍처, 활용방안 3. 적재 파일럿 실행 1단계 - 적재 아키텍쳐 4. 적재 파일럿 실행 2단계 - 적재 환경구성. 5. 적재 파일럿 실행 3단계 - 적재 기능 구현 6. 적재 파일럿 실행 4단계 - 적재 기능 테스트 |
ps -ef |grep smartcar.log
https://flume.apache.org/FlumeUserGuide.html
| channel | – | |
| type | – | The component type name, needs to be hdfs |
| hdfs.path | – | HDFS directory path (eg hdfs://namenode/flume/webdata/) |
| hdfs.filePrefix | FlumeData | Name prefixed to files created by Flume in hdfs directory |
| hdfs.fileSuffix | – | Suffix to append to file (eg .avro - NOTE: period is not automatically added) |
| hdfs.inUsePrefix | – | Prefix that is used for temporal files that flume actively writes into |
| hdfs.inUseSuffix | .tmp | Suffix that is used for temporal files that flume actively writes into |
| hdfs.emptyInUseSuffix | false | If false an hdfs.inUseSuffix is used while writing the output. After closing the output hdfs.inUseSuffix is removed from the output file name. If true the hdfs.inUseSuffix parameter is ignored an empty string is used instead. |
| hdfs.rollInterval | 30 | Number of seconds to wait before rolling current file (0 = never roll based on time interval) |
| hdfs.rollSize | 1024 | File size to trigger roll, in bytes (0: never roll based on file size) |
| hdfs.rollCount | 10 | Number of events written to file before it rolled (0 = never roll based on number of events) |
| hdfs.idleTimeout | 0 | Timeout after which inactive files get closed (0 = disable automatic closing of idle files) |
| hdfs.batchSize | 100 | number of events written to file before it is flushed to HDFS |
| hdfs.codeC | – | Compression codec. one of following : gzip, bzip2, lzo, lzop, snappy |
| hdfs.fileType | SequenceFile | File format: currently SequenceFile, DataStream or CompressedStream (1)DataStream will not compress output file and please don’t set codeC (2)CompressedStream requires set hdfs.codeC with an available codeC |
| hdfs.maxOpenFiles | 5000 | Allow only this number of open files. If this number is exceeded, the oldest file is closed. |
| hdfs.minBlockReplicas | – | Specify minimum number of replicas per HDFS block. If not specified, it comes from the default Hadoop config in the classpath. |
| hdfs.writeFormat | Writable | Format for sequence file records. One of Text or Writable. Set to Text before creating data files with Flume, otherwise those files cannot be read by either Apache Impala (incubating) or Apache Hive. |
| hdfs.threadsPoolSize | 10 | Number of threads per HDFS sink for HDFS IO ops (open, write, etc.) |
| hdfs.rollTimerPoolSize | 1 | Number of threads per HDFS sink for scheduling timed file rolling |
| hdfs.kerberosPrincipal | – | Kerberos user principal for accessing secure HDFS |
| hdfs.kerberosKeytab | – | Kerberos keytab for accessing secure HDFS |
| hdfs.proxyUser | ||
| hdfs.round | false | Should the timestamp be rounded down (if true, affects all time based escape sequences except %t) |
| hdfs.roundValue | 1 | Rounded down to the highest multiple of this (in the unit configured using hdfs.roundUnit), less than current time. |
| hdfs.roundUnit | second | The unit of the round down value - second, minute or hour. |
| hdfs.timeZone | Local Time | Name of the timezone that should be used for resolving the directory path, e.g. America/Los_Angeles. |
| hdfs.useLocalTimeStamp | false | Use the local time (instead of the timestamp from the event header) while replacing the escape sequences. |
| hdfs.closeTries | 0 | Number of times the sink must try renaming a file, after initiating a close attempt. If set to 1, this sink will not re-try a failed rename (due to, for example, NameNode or DataNode failure), and may leave the file in an open state with a .tmp extension. If set to 0, the sink will try to rename the file until the file is eventually renamed (there is no limit on the number of times it would try). The file may still remain open if the close call fails but the data will be intact and in this case, the file will be closed only after a Flume restart. |
| hdfs.retryInterval | 180 | Time in seconds between consecutive attempts to close a file. Each close call costs multiple RPC round-trips to the Namenode, so setting this too low can cause a lot of load on the name node. If set to 0 or less, the sink will not attempt to close the file if the first attempt fails, and may leave the file open or with a ”.tmp” extension. |
| serializer | TEXT | Other possible options include avro_event or the fully-qualified class name of an implementation of the EventSerializer.Builder interface. |
| serializer.* |
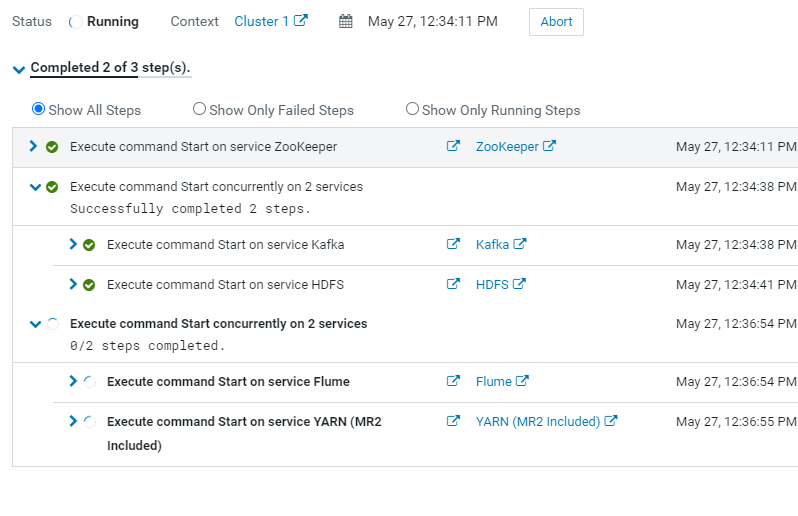
크러스터 시작시 : 주키퍼 > 카프카> HDFS > Flume > YARN 순으로 기동.
'Data' 카테고리의 다른 글
| [1028 from 실무로 배우는 빅데이터 기술 By 김강원 11]주키퍼 (0) | 2021.05.26 |
|---|---|
| [1028 from 실무로 배우는 빅데이터 기술 By 김강원 10]하둡 (0) | 2021.05.26 |
| [1028 from 실무로 배우는 빅데이터 기술 By 김강원 08]수집- 카프카 (0) | 2021.05.24 |
| [1028 from 실무로 배우는 빅데이터 기술 By 김강원 07]수집- 플럼 (0) | 2021.05.24 |
| [1028 from 실무로 배우는 빅데이터 기술 By 김강원 06]수집- 개요/아키텍처 (0) | 2021.05.24 |